Optimizasyon kavramı dijital ürün ve servislerle aynı cümle içerisinde kullanılmaya başladı başlayalı, A/B testlerinin popülaritesi tavan yaptı. Fakat A/B testlerinin geçerli olabilmesi için hayati önem taşıyan bir unsur var: İstatistiksel anlamlılık (Statistical Significance). Bunun ne anlama geldiğini ve A/B testlerini nasıl etkilediğini beraber inceleyelim.
Optimizasyon kavramı dijital ürün ve servislerle aynı cümle içerisinde kullanılmaya başladı başlayalı, A/B testlerinin popülaritesi tavan yaptı. Fakat A/B testlerinin geçerli olabilmesi için hayati önem taşıyan bir unsur var: Statistical Significance (İstatistiksel anlamlılık). Bunun ne anlama geldiğini ve A/B testlerini nasıl etkilediğini beraber inceleyelim.
UX Analytics Manager’ımız Alper Gökalp, önceki aylarda A/B testlerini e-ticaret perspektifinden değerlendiren, bir hayli de ilgi gören bir makale kaleme almıştı. Ben bu makaleyi tamamlayan ve aynı zamanda dönüşüm optimizasyonu konusunda hizmet aldığınız profesyonellerin yetkinliklerini ölçmekte kullanabileceğiniz ipuçlarını barındıran bir özet hazırladım.
İstatistiksel anlamlılık kavramı, dijital ürün veya servisinizde yürüttüğünüz optimizasyon çalışmaları sırasında yürüttüğümüz hipotez geliştirme ve hipotezlerimizi test ederek karar alma sürecinde karşımıza sıklıkla çıkan bir “kontrol noktası” olarak tanımlanabilir. Bu kontrol noktası, test sonuçlarının istatistiksel olarak anlamlı olabilmesi için hayati değer taşıyan bir sağlamadır. Test süreçlerinde “Kestane kebap, bizim teste acil cevap” isteğiyle üzerinize dalga dalga gelen HiPPO (highest paid person’s opinion) baskısını, “Kusuruma bakma, henüz istatistiksel olarak anlamlı sonuç verecek noktada değiliz.” şeklinde özetlenebilecek, cool ve etkili bir yanıtla savuşturmanızı mümkün kılar.
Bu içerik ücretsiz!
Okumaya devam etmek ve SHERPA Blog okuru olmak için aşağıdakilerden birini seç. Her hafta yenileri eklenen yüzlerce içeriğe ücretsiz ve sınırsız eriş.
Anlamlılık seviyesi, istatistik biliminde, İngiliz istatistikçi Ronald Fisher tarafından çıkartımsalhipotez sınama yönteminin kurulması sırasında kavramlaştırılmış, özel bir manası olan bir bilimsel ve istatistiksel terimdir. İstatistiksel anlamlılık ise, eğer bir sonucun olabilirliği, gerçekleşme olasılık değerlendirilmesine göre düşük değil ise ortaya çıkar.[1]
Bu açıklamayı hazmedebilmek için gelin, kendimize bir soru soralım. Web sitemizin ana sayfasındaki showcase alanında yer alan görseller arasında ilerlemek için kullandığımız butonları ele alalım. Diyelim ki, bu butonların pozisyonlarından ve performansından mutlu değiliz ve bunu iyileştirmek için bir hipotez geliştirdik.
Bu hipotezin, başarılı olup olmadığını anlamak için yaptığımız testi başarılı veya başarısız olarak kabul etmek için neye ihtiyacımız var?
İşte istatistik biliminde buradaki “ne”nin karşılığı, test sonuçlarının anlamlılık seviyesi ya da istatistiksel olarak doğruluğu şeklinde tanımlanıyor.
Eğer bir test, anket ya da veri analizi esnasında, sonuçları sonsuza varan sürelerde almak istemeyen bir analistseniz; veri içerisinden bir örneklem alarak çalışırsınız. Seçim anketlerinden aşina olduğumuz bu yöntem, her bir veriyi tek tek toplamaya çalışmak yerine, hızlı sonuç alabilmek için üretilmiş bir metodolojidir. Ancak bu metodolojinin bir hayli dikkatli kullanılması gerekir. Çünkü en basit anlatımıyla; analiz etmek istediğiniz veri seti içinden örneklem olarak belirlediğiniz alanı, verinin setinin geneline yönelik bir çıkarımda bulunabilmesine imkan vermeyecek şekilde “seçtiyseniz”, sonuçlarınız da tamamen hatalı çıkacaktır. İşte bu seçim işlemine “örneklem yaratma” diyoruz.
Örneklem hesaplamada en sık karşılaştığımız hataların sebeplerini açıklayarak, sonu Statistical Significance’a çıkan hikayemizde bize çok yardımcı olayım.
En bariz hatalar
Bugüne kadar yürüttüğümüz, kulak misafiri olduğumuz ya da raporunu incelediğimiz A/B testlerinde en çok aşağıdaki iki başlıkta hata tespit ettik:
Örneklem hacmi (“Toplam verinin ne kadarını alıp, incelerseniz anlamlı sonuçlara sahip olursunuz?” sorusunun yanıtı.)
Test varyasyonundan toplanacak verinin hacmi (“Optimize etmeye çalıştığınız alanda yürüttüğünüz deneyin, hangi hacimdeki bir test verisi üzerinde deneye tabi tutulması gerekiyor?” sorusuna vereceğiniz yanıt.)
Basit bir örnekle konuya açıklık getirelim. Diyelim ki yeni bir kampanyanın testini yapıyorsunuz ve bu kampanyaya tabi tutulan (bir diğer deyişle onu gören) kullanıcılarınızın harcama ortalaması 10 TL; diğer kullanıcılarınki (kampanyanızı görmeyenlerin) ise 8 TL. Tez canlı bir profesyonel için “2 TL’lik ortalama fark yakaladık!” sonucuyla müdürün odasına koşturmak gayet alışılagelmiş bir tepki. Eğer bu arkadaşımızın, müdürünün kendisine gelişine çakacağı “Kampanyayı gösterdiğiniz örneklemin detaylarını gösterebilir misin?” sorusuyla nakavt olmak gibi bir derdi yoksa; yazının bundan sonrasını okumayabilir. Zira istatistik bir bilim ve açıkçası tez canlılığı pek de sevmiyor.
Örnekleminiz ana veri kümesinin ne kadar yüksek oranında bir hacme sahipse ve ne kadar doğru şekilde tanımlandıysa o kadar anlamlı bir sonuç verecektir. Eğer yukarıdaki kampanyayı, toplamda 1.000 kullanıcısı olan bir dijital platformun kullanıcılarının sadece %1’lik bir bölümüne gösteriyor ve bu 10 kullanıcıdan alınan ortalama değere göre karar veriyorsak; çok düşük bir istatiksel doğruluk payı ile sonuca ulaşmaya çalışıyoruz demektir.
Peki, “standart sapma” ne oluyor?
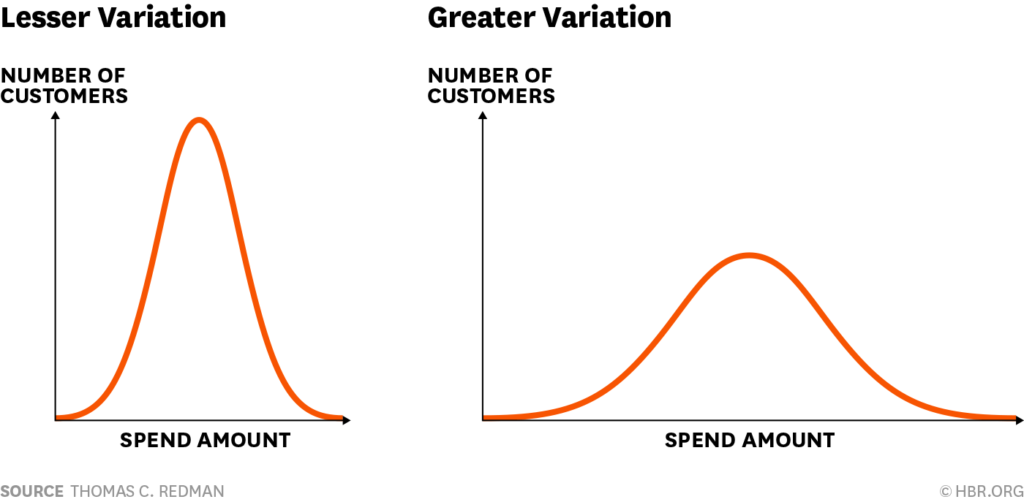
Basit bir tanımla standart sapma, test verisinde göreceğimiz çeşitliliktir. Yani, topladığınız her bir verinin, toplam verinin ortalamasına olan uzaklığını ifade eder. Data Driven: Profiting from Your Most Important Business Asset kitabının yazarı Tom Redman‘ın aşağıdaki örneği standart sapmanın ne olduğunu anlatırken bize yardımcı olacak:
Her iki görsel de az önce örnek aldığımız kampanyaya tabi olan kullanıcıların sayısı ve harcama tutarlarındaki dağılımları gösteriyor. Soldaki görselde yer alan grafikteki harcama tutarlarının birbirlerine benzerlik gösterdiğini ve büyük çoğunluğun aynı ortalama değerlere yakın olduğunu görüyoruz. Diğer bir deyişle, veri seti içerisinden ayrıştıracağımız örneklemlerde, farklı sonuçlar görebilmemizin ihtimali düşük.
Sağdaki görselde ise, ortalama harcama tutarlarındaki değişkenlik çok daha geniş bir alana dağılıyor. Elde edeceğimiz sonuç, veri seti içerisinden ayrıştıracağımız örneklemin nereden alınacağına göre ciddi farklılıklar gösterebiliyor.
Eğer testlerimizi uygulayacağımız veri seti içerisindeki standart sapma ne kadar yüksek ise, örneklem boyutunun yetersizliğinden kaynaklanan hata riski de bir o kadar yüksek olacaktır.
Son olarak
Bu makaleyi, bir hayli teknik bir konuyu, istatistik bilgisi çok az veya az seviyede olan SHERPA Blog okuyucularını hedefleyerek hazırladım. İstatistik hakkında ahkam kesmek; günlük hayatta cümle içinde kullanmadığımız birçok kavram ve terimi bilmeyi, örnekleriyle incelemiş olmayı ve tabi ki, karar vermeden önce mutlaka deney yaparak gözlemlemeyi esas alıyor. A/B testleri bugünün popüler kültüründe kendisine hiç olmadığı kadar yer bulduysa; bu durum en çok, yıllarını istatistik alanında öğrenmeye, öğretmeye ve sorgulamaya adamış olan bilim insanlarını sevindiriyor olmalı. Bu özet giriş yazısını daha detaylı bir versiyonuyla pekiştireceğimi ve gerçek bir A/B test örneğinin ekran görüntülerinin üzerine inşa ederek devam ettireceğimi eklemek isterim.